This article focuses on a set of functions that can be used for text mining with Spark and sparklyr. The main goal is to illustrate how to perform most of the data preparation and analysis with commands that will run inside the Spark cluster, as opposed to locally in R. Because of that, the amount of data used will be small.
Data source
For this example, there are two files that will be analyzed. They are both the full works of Sir Arthur Conan Doyle and Mark Twain. The files were downloaded from the Gutenberg Project site via the gutenbergr package. Intentionally, no data cleanup was done to the files prior to this analysis. See the appendix below to see how the data was downloaded and prepared.
The spark_read_text() is a new function which works like readLines() but for sparklyr. It comes in handy when non-structured data, such as lines in a book, is what is available for analysis.
# Imports Mark Twain's filetwain_path<-paste0("file:///", here::here(), "/mark_twain.txt")twain<-spark_read_text(sc, "twain", twain_path)
# Imports Sir Arthur Conan Doyle's filedoyle_path<-paste0("file:///", here::here(), "/arthur_doyle.txt")doyle<-spark_read_text(sc, "doyle", doyle_path)
Data transformation
The objective is to end up with a tidy table inside Spark with one row per word used. The steps will be:
The needed data transformations apply to the data from both authors. The data sets will be appended to one another
Punctuation will be removed
The words inside each line will be separated, or tokenized
For a cleaner analysis, stop words will be removed
To tidy the data, each word in a line will become its own row
The results will be saved to Spark memory
sdf_bind_rows()
sdf_bind_rows() appends the doyle Spark Dataframe to the twain Spark Dataframe. This function can be used in lieu of a dplyr::bind_rows() wrapper function. For this exercise, the column author is added to differentiate between the two bodies of work.
The Hive UDF, regexp_replace, is used as a sort of gsub() that works inside Spark. In this case it is used to remove punctuation. The usual [:punct:] regular expression did not work well during development, so a custom list is provided. For more information, see the Hive Functions section in the dplyr page.
# Source: spark<?> [?? x 3]
line author word_list
<chr> <chr> <list>
1 cover doyle <list [1]>
2 The Return of Sherlock Holmes doyle <list [5]>
3 by Sir Arthur Conan Doyle doyle <list [5]>
4 Contents doyle <list [1]>
ft_stop_words_remover()
ft_stop_words_remover() is a new function that, as its name suggests, takes care of removing stop words from the previous transformation. It expects a list column, so it is important to sequence it correctly after a ft_tokenizer() command. In the sample results, notice that the new wo_stop_words column contains less items than word_list.
# Source: spark<?> [?? x 4]
line author word_list wo_stop_words
<chr> <chr> <list> <list>
1 cover doyle <list [1]> <list [1]>
2 The Return of Sherlock Holmes doyle <list [5]> <list [3]>
3 by Sir Arthur Conan Doyle doyle <list [5]> <list [4]>
4 Contents doyle <list [1]> <list [1]>
explode()
The Hive UDF explode performs the job of unnesting the tokens into their own row. Some further filtering and field selection is done to reduce the size of the dataset.
# Source: spark<?> [?? x 2]
word author
<chr> <chr>
1 cover doyle
2 return doyle
3 sherlock doyle
4 holmes doyle
compute()
compute() will operate this transformation and cache the results in Spark memory. It is a good idea to pass a name to compute() to make it easier to identify it inside the Spark environment. In this case the name will be all_words
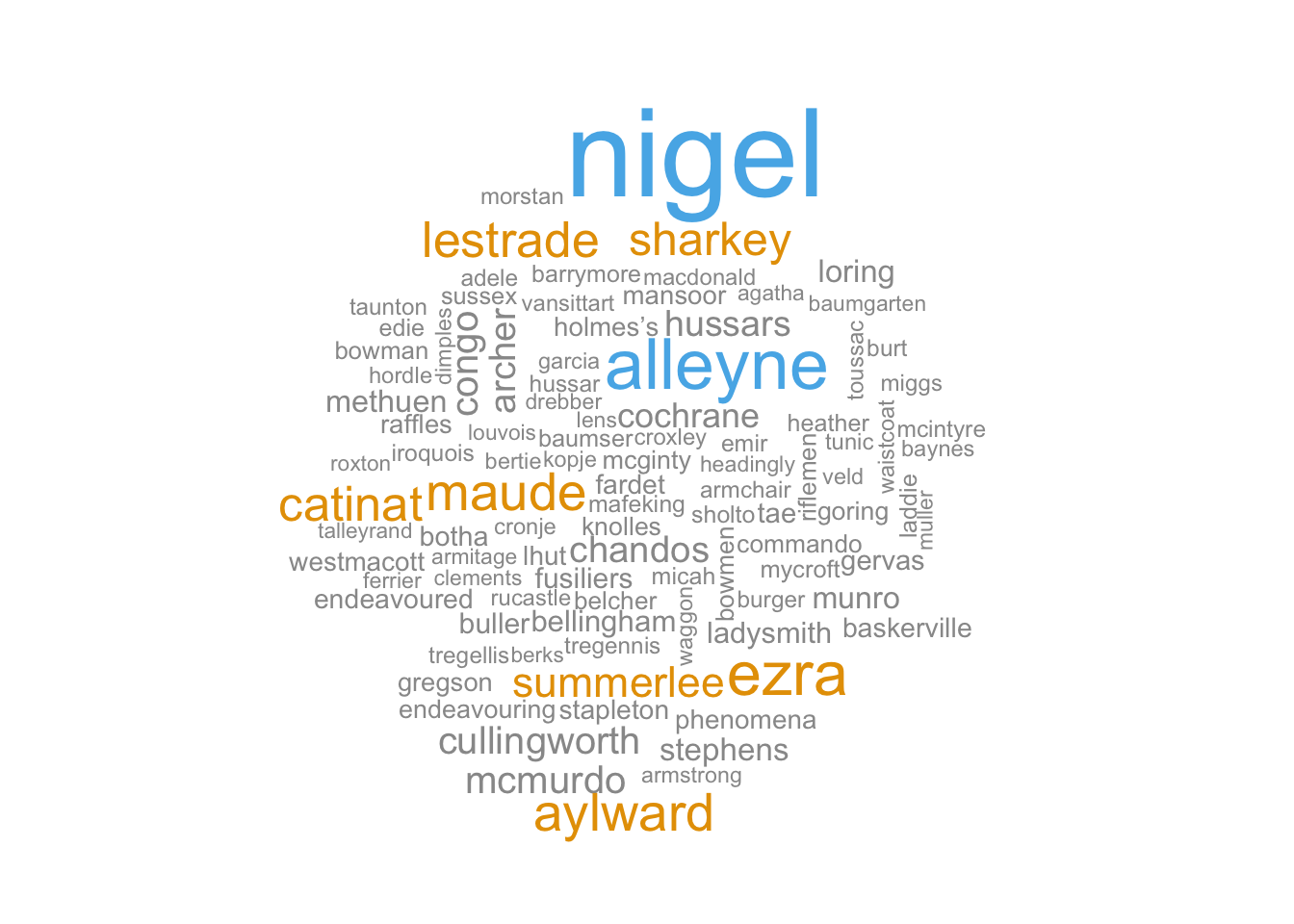
The word cloud highlighted something interesting. The word “lestrade” is listed as one of the words used by Doyle but not Twain. Lestrade is the last name of a major character in the Sherlock Holmes books. It makes sense that the word “sherlock” appears considerably more times than “lestrade” in Doyle’s books, so why is Sherlock not in the word cloud? Did Mark Twain use the word “sherlock” in his writings?
The all_words table contains 16 instances of the word sherlock in the words used by Twain in his works. The instr Hive UDF is used to extract the lines that contain that word in the twain table. This Hive function works can be used instead of base::grep() or stringr::str_detect(). To account for any word capitalization, the lower command will be used in mutate() to make all words in the full text lower cap.
instr() & lower()
Most of these lines are in a short story by Mark Twain called A Double Barrelled Detective Story. As per the Wikipedia page about this story, this is a satire by Twain on the mystery novel genre, published in 1902.
[1] "late sherlock holmes, and yet discernible by a member of a race charged"
[2] "sherlock holmes."
[3] "“uncle sherlock! the mean luck of it!--that he should come just"
[4] "another trouble presented itself. “uncle sherlock 'll be wanting to talk"
[5] "flint buckner's cabin in the frosty gloom. they were sherlock holmes and"
[6] "“uncle sherlock's got some work to do, gentlemen, that 'll keep him till"
[7] "“by george, he's just a duke, boys! three cheers for sherlock holmes,"
[8] "he brought sherlock holmes to the billiard-room, which was jammed with"
[9] "of interest was there--sherlock holmes. the miners stood silent and"
[10] "the room; the chair was on it; sherlock holmes, stately, imposing,"
[11] "“you have hunted me around the world, sherlock holmes, yet god is my"
[12] "“if it's only sherlock holmes that's troubling you, you needn't worry"
[13] "they sighed; then one said: “we must bring sherlock holmes. he can be"
[14] "i had small desire that sherlock holmes should hang for my deeds, as you"
[15] "“my name is sherlock holmes, and i have not been doing anything.”"
[16] "late sherlock holmes, and yet discernible by a member of a race charged"