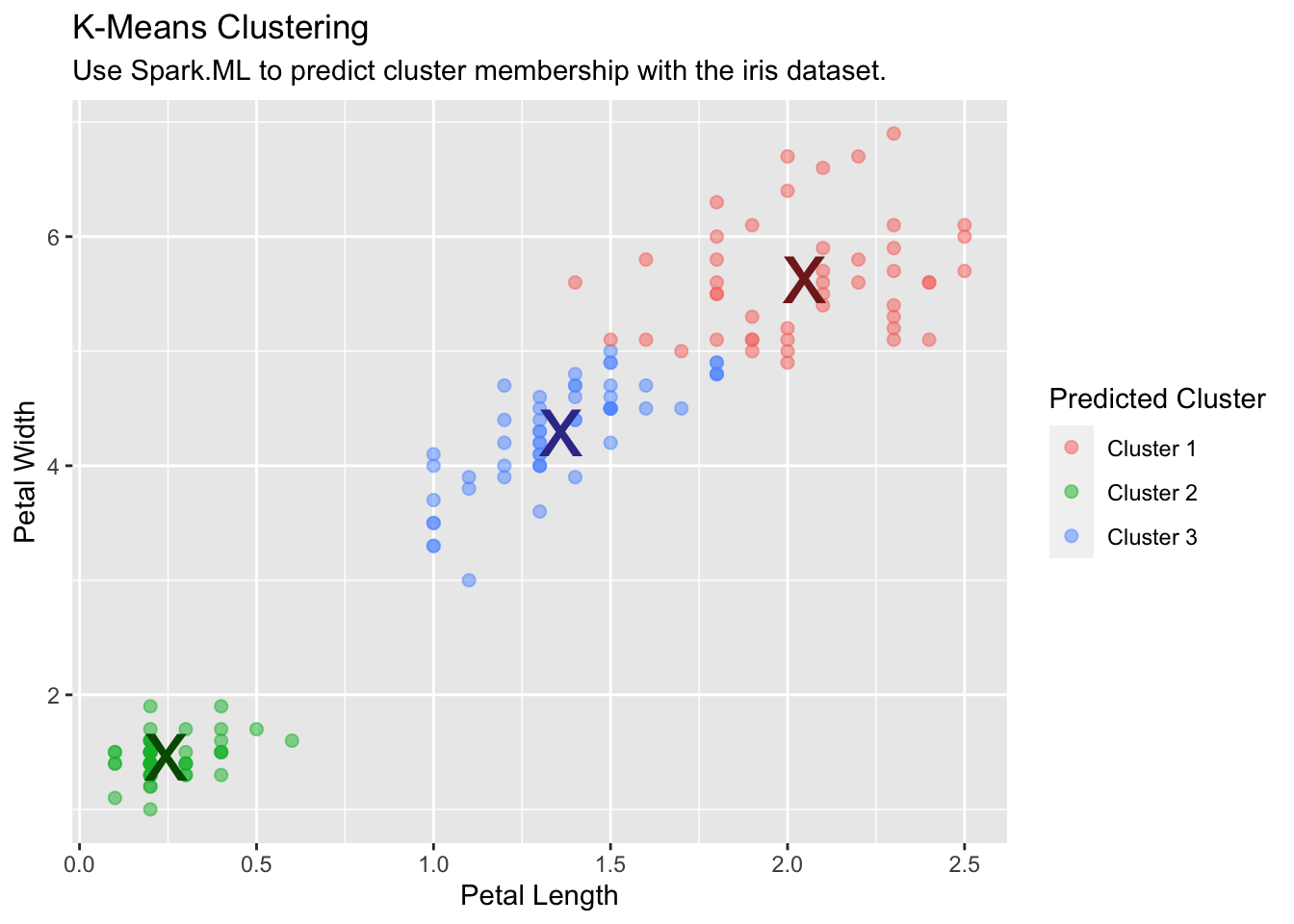
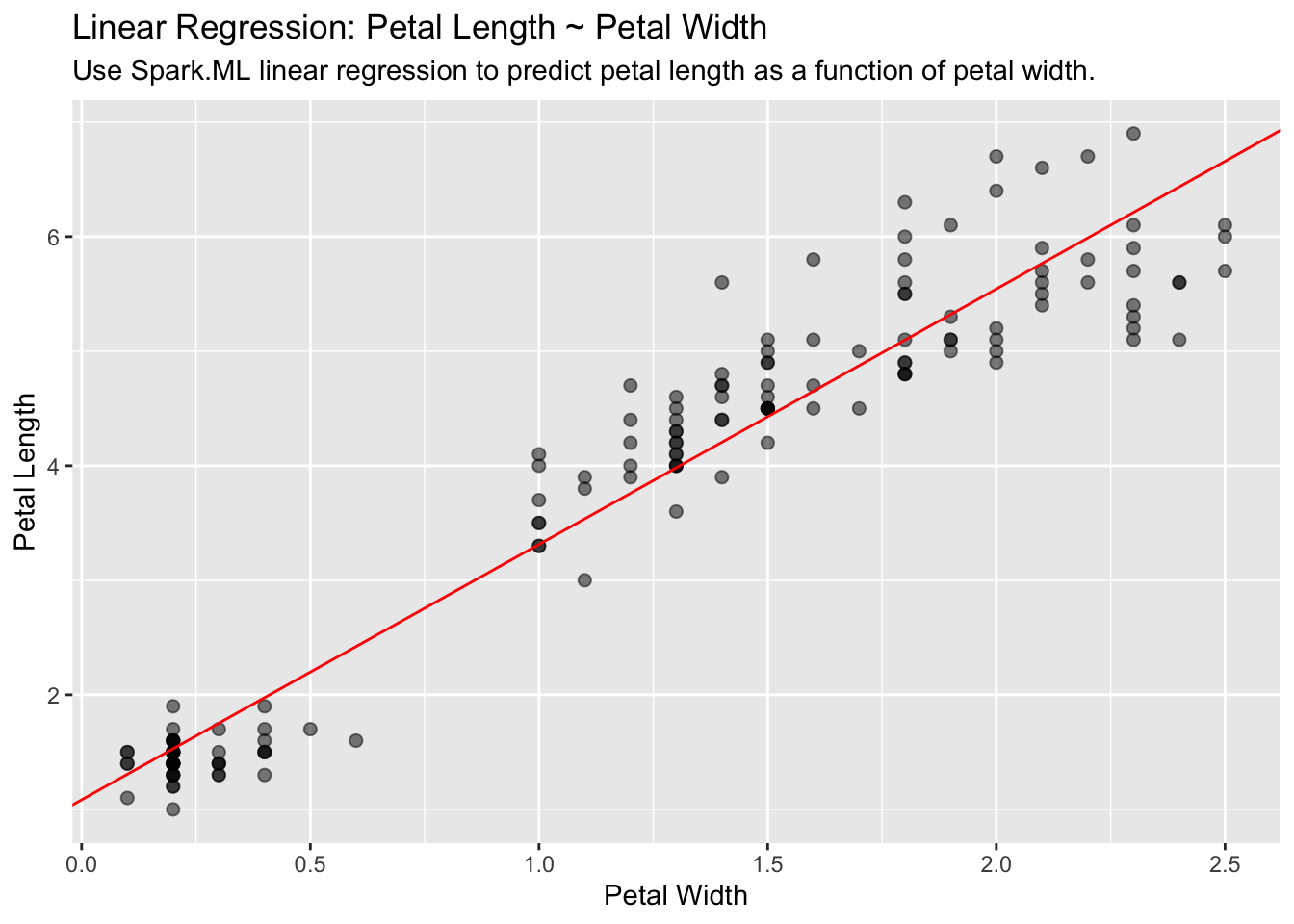
Columns: 14
Database: spark_connection
$ Sepal_Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.…
$ Sepal_Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.…
$ Petal_Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.…
$ Petal_Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.…
$ Species <chr> "setosa", "setosa", "setosa", "setosa", "setosa…
$ features <list> <1.4, 0.2>, <1.4, 0.2>, <1.3, 0.2>, <1.5, 0.2>…
$ label <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ rawPrediction <list> <20, 0, 0>, <20, 0, 0>, <20, 0, 0>, <20, 0, 0>…
$ probability <list> <1, 0, 0>, <1, 0, 0>, <1, 0, 0>, <1, 0, 0>, <1…
$ prediction <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ predicted_label <chr> "setosa", "setosa", "setosa", "setosa", "setosa…
$ probability_setosa <dbl> 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.…
$ probability_versicolor <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.…
$ probability_virginica <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…