Option 1 - Connecting to Databricks remotely
Overview
With this configuration, RStudio Workbench is installed outside of the Spark cluster and allows users to connect to Spark remotely using sparklyr with Databricks Connect.
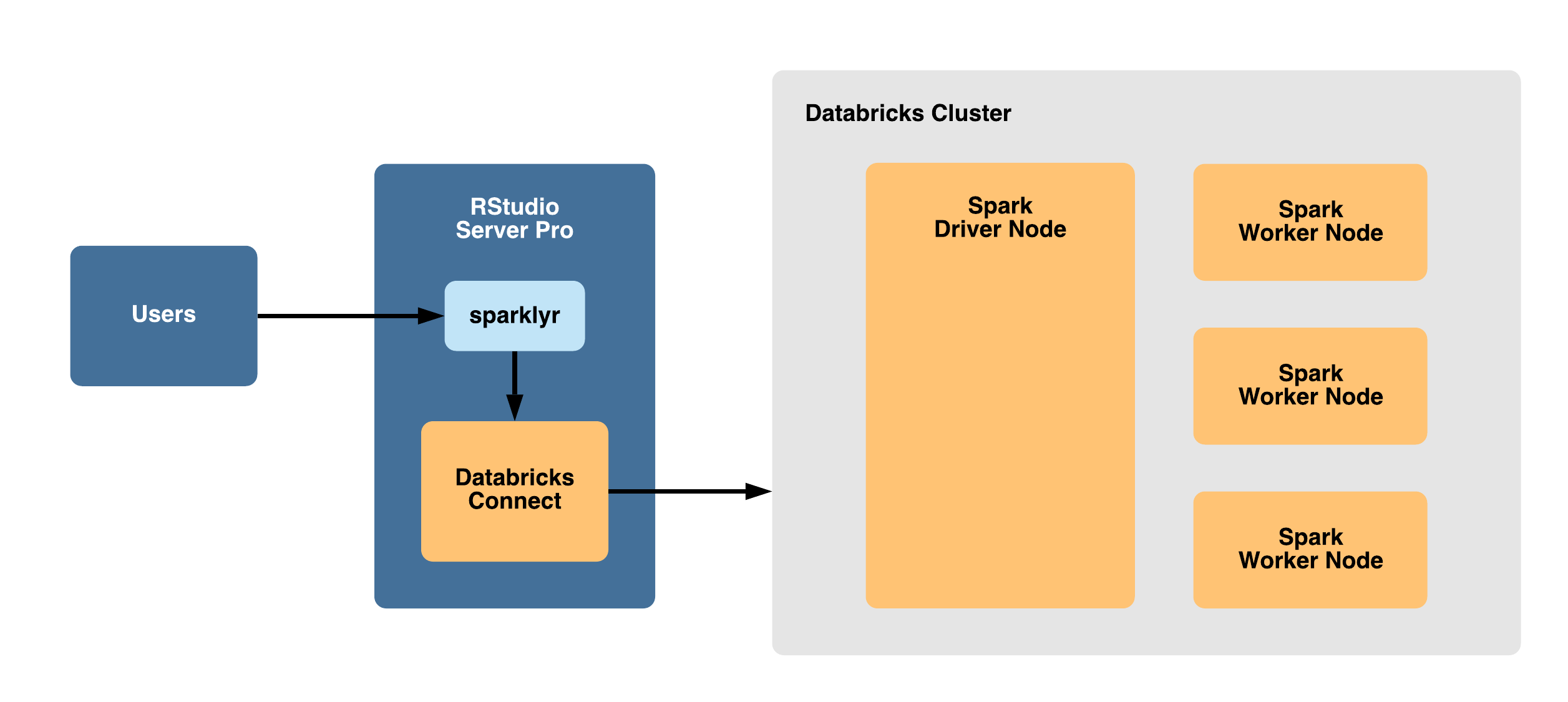
This is the recommended configuration because it targets separate environments, involves a typical configuration process, avoids resource contention, and allows RStudio Workbench to connect to Databricks as well as other remote storage and compute resources.
Advantages and limitations
Advantages:
- RStudio Workbench will remain functional if Databricks clusters are terminated
- Provides the ability to communicate with one or more Databricks clusters as a remote compute resource
- Avoids resource contention between RStudio Workbench and Databricks
Limitations:
- Databricks Connect does not currently support the following APIs from
sparklyr: Broom APIs, Streaming APIs, Broadcast APIs, Most MLlib APIs,csv_fileserialization mode, and thespark_submitAPI - Databricks Connect does not support structured streaming
- Databricks Connect does not support running arbitrary code that is not a part of a Spark job on the remote cluster
- Databricks Connect does not support Scala, Python, and R APIs for Delta table operations
- Databricks Connect does not support most utilities in Databricks Utilities. However,
dbutils.fsanddbutils.secretsare supported
For more information on the limitations of Databricks Connect, refer to the Limitation section of the Databricks Connect documentation.
Requirements
- RStudio Workbench installed outside of the Databricks cluster
- Java 8 installed on the machine with RStudio Workbench
- A running Databricks cluster with a runtime version 5.5 or above
Install Python
The Databricks Connect client is provided as a Python library. The minor version of your Python installation must be the same as the minor Python version of your Databricks cluster.
Refer to the steps in the install Python section of the RStudio Documentation to install Python on the same server where RStudio Workbench is installed.
Note that you can either install Python for all users in a global location (as an administrator) or in a home directory (as an end user).
Install Databricks Connect
Run the following command to install Databricks Connect on the server with RStudio Workbench:
pip install -U databricks-connect==6.3.* # or a different version to match your Databricks clusterNote that you can either install this library for all users in a global Python environment (as an administrator) or for an individual user in their Python environment (e.g., using the pip --user option or installing into a conda environment or virtual environment).
Configure Databricks Connect
To configure the Databricks Connect client, you can run the following command in a terminal when logged in as a user in RStudio Workbench:
databricks-connect configureIn the prompts that follow, enter the following information:
| Parameter | Description | Example Value |
|---|---|---|
| Databricks Host | Base address of your Databricks console URL | https://dbc-01234567-89ab.cloud.databricks.com |
| Databricks Token | User token generated from the Databricks Console under your “User Settings” | dapi24g06bdd96f2700b09dd336d5444c1yz |
| Cluster ID | Cluster ID in the Databricks console under Advanced Options > Tags > ClusterId
|
0308-033548-colt989 |
| Org ID | Found in the ?o=orgId portion of your Databricks Console URL |
8498623428173033 |
| Port | The port that Databricks Connect connects to | 15001 |
After you’ve completed the configuration process for Databricks Connect, you can run the following command in a terminal to test the connectivity of Databricks Connect to your Databricks cluster:
databricks-connect testInstall sparklyr
The integration of sparklyr with Databricks Connect is currently being added to the development version of sparklyr. To use this functionality now, you’ll need to install the development version of sparklyr by running the following command in an R console:
devtools::install_github("sparklyr/sparklyr")Install Spark
To work with a remote Databricks cluster, you need to have a local installation of Spark that matches the version of Spark on the Databricks Cluster.
You can install Spark by running the following command in an R console:
library(sparklyr)
sparklyr::spark_install()Use sparklyr
In order to connect to Databricks using sparklyr and databricks-connect, SPARK_HOME must be set to the output of the databricks-connect get-spark-home command.
You can set SPARK_HOME as an environment variable or directly within spark_connect(). The following R code demonstrates connecting to Databricks, copying some data into the cluster, summarizing that data using sparklyr, and disconnecting:
library(sparklyr)
library(dplyr)
databricks_connect_spark_home <- system("databricks-connect get-spark-home", intern = TRUE)
sc <- spark_connect(method = "databricks", spark_home = databricks_connect_spark_home)
cars_tbl <- copy_to(sc, mtcars, overwrite = TRUE)
cars_tbl %>%
group_by(cyl) %>%
summarise(
mean_mpg = mean(mpg, na.rm = TRUE),
mean_hp = mean(hp, na.rm = TRUE)
)
spark_disconnect(sc)Additional information
For more information on the setup, configuration, troubleshooting, and limitations of Databricks Connect, refer to the Databricks Connect section of the Databricks documentation.